

One of the biggest problems we have at ZK Email is that old emails are signed with public keys that are expired and not stored anywhere. This is because DKIM keys rotate at some frequency, and no one is keeping track of what the old DKIM keys are -- the DNS record is simply overwritten. This makes it very hard to verify old emails, ZK or not, and is also a problem for when e.g. lawyers need to verify leaked emails in general.
So we set out to create the largest registry of such keys, and here's how we did it. Note that nearly all the discussion and engineering happened over open source Github issues, so definitely search there for more details.
Table of Contents
Getting Selectors
The Scrape
The Hack
The Reverse Engineer
The Future
Getting Selectors
The main issue with just getting and storing the keys is that we have no idea where they live -- even if we know that, say, google.com has a DKIM key, because DNS works via a query system (you cannot just query all records), you need to know the DKIM selector as well. The selector is the field in s= in an email; for instance, for Outlook that selector is usually something like selector1 or selector2, and for Gmail it's usually something like 20230601, representing June 1 2023 as being the date that the key last rotated. This means that Gmail's DKIM key is stored on DNS as 20230601._domainkey.gmail.com. Then, we can hit DNS and retrieve the RSA public key. As a reminder, RSA public keys are n = pq, basically a large 2048-bit value with exactly two large prime factors.
(I would love to be proved wrong here by the way -- if anyone runs a DNS server or something and knows of some obscure setting that lets someone dump all values at a subdomain or make a broader query, please let me know! That would save us a LOT of effort. We have not found any methods so far that work for DKIM keys, though many websites purport to do it for root level records.)
So how do we get selectors? The way the archive works is that users contribute all the selectors in their inbox. We can do it automatically, for instance if the user goes to the contribute page, and then connects their Gmail account with metadata access (we also have a flow to run the process with a local download for non-Gmail accounts or privacy-conscious folks). We have a script that automatically loops on just their email headers, then retrieves the selectors, then runs a server to check if those entries really exist, and if they do, then retrieve the keys and stores them.
Wen decentralization?
There isn't a great way to get decentralization levels of security on this unfortunately -- there is no signature on these values unless they use DNSSEC (we have an open issue to cache those DNSSEC signatures, which we don't currently get). We could get some Aptos validators or ICP canisters to verify so that we can get some rough consensus from at least more than one computer, but it's basically impossible to verify that someone did a DNS get correctly. One alternative is to have each user notarize via TLS notary that they fetched the keys correctly from i.e. both Google's DNS-over-TLS API and Cloudflare's API and got that answer, but the cost overhead on that would be quite annoying given the number of email servers that exist.
We decided for now to just do the simplest, centralized thing first -- our server verifies all keys coming in and out of the system, and is the only trusted party right now. We also timestamp them with witness.co so that when you retrieve a key, you learn a verifiable date that we actually archived it (so you can at least verify that we aren't making up keys on the spot, though it doesn't add any real security to the keys). We should enable signatures on API requests for records the archive serves so that they can be verified elsewhere (it's an open issue). We hope that someone can also help contribute a more fleshed out attestation style system to get higher economic security guarantees on each key. We could also have a system where many organizations all individually verify and attest to the keys.
What We Found
With just this system and basically all of our friends and teammates uploading selectors (and also uploading selectors from large email leaks like Clinton's), we were able to get to something like 9,000 unique domains and ~3,000 unique selectors. There are some interesting statistics to note here -- AmazonSES for instance, has a basically random, long, alphanumeric selector for each domain using them to host email. It would be great to know if this was a hash of something intuitive like the domain name or something, since then we wouldn't have to upload these websites' selectors one at a time, and we could programmatically scrape and archive them without needing a raw email to extract the selector from. We have a comprehensive list of the relative frequency of each selector and frequency of reused DKIM keys -- you can see selectors like 'k2' and 'k3' are very common, and their keys are reused across over 40,000 domains -- these likely correspond to Mailchimp. You can see what selectors correspond to which domains here.
The Scrape
Armed with these ~3,000 selectors, we tried the next intuitive step: combine it with every list of selectors we could find on Github, then run it on the Alexa top million domains. We found a few thousand selector-long lists, and adding those lists of selectors took us to about ~4,500 selectors. There are more lists like this cool dkimscan Perl script with common patterns encoded as well, but we didn't get a chance to use this specific one. We then used modal.com to run a massive, distributed scrape of DNS for all of these million domains, and each selector that had appeared at least twice in the dataset (to mostly exclude those pesky per-domain AmazonSES keys). Each DNS query takes something like .1 seconds to return, so we burned something like 3 years of CPU time on modal for $360 and got them all in a few days. You can run this scrape yourself with our script here. This took us to about a million selector-domain keys, meaning we found an average of one match per domain! This is of course super skewed by domains with like 10+ selector matches, but is a great result nonetheless.
Oddly, we found a lot of selectors and public keys that existed for well known websites but we couldn't seem to find any emails for -- perhaps they are used for internal emails or a specific kind of notification/business email.
We then continue to run our cronjob scraper daily to see when keys refresh. Due to cost, we only do this for domains that have been manually added via inbox addition to the archive, not the ones that we got from the million domain scrape -- this is how we ensure our computing resources are being used to archive the most interesting keys, of emails that people actually received and not just orphaned keys. If we had more budget, we would run the scraper on all the domains instead.
The Hack
Now that we have this enormous set of DKIM keys, it turns out that it gives us great leverage to try to find insecurely generated keys. A little known hack (but one of my favorites) involves breaking RSA keys for which insecure randomness generators are used. It exploits the fact that if two different keys share one prime factor in common, then you can simply take their GCD to break the prime factorization and find the secret keys for both of those RSA keys.
So now we had the question: were any of these email servers secretly using very bad randomness generators, and had possibly emitted keys that we could break? Running this brute force on keys pairwise would take about 10^12 2048-bit GCDs to check, which is infeasible, but it turns out that there's a very efficient way to batch keys into a tree structure and effectively make this log linear instead of quadratic -- here's a great blog post explaining it. So we found a repo that implemented this, optimized it a bit more, then ran it on our whole database.
We kept this plan, PRs, and code secret during development in case we did actually find critical vulnerabilities -- at the end of this, we did not learn any secret keys (meaning most DKIM keys are at least not obviously insecure)! So we open sourced the code -- but we found something much stranger, which was a littering of small prime factors under a thousand, meaning that either some keys were REALLY bad, or somehow a third small prime factor crept into these keys. We still need to run the AKS or proabilitistic primality test on the RSA keys dividided by those small prime factors to see if one of those small keys is actually the secret key, which we decided would be insane enough that we didn't do it yet.
There were a lot of cool results from this analysis that we will publish shortly as well!
The Reverse Engineer
This is where the real magic starts. The whole problem we wanted to solve in the first place, was how to verify old emails and recover old, expired public keys.
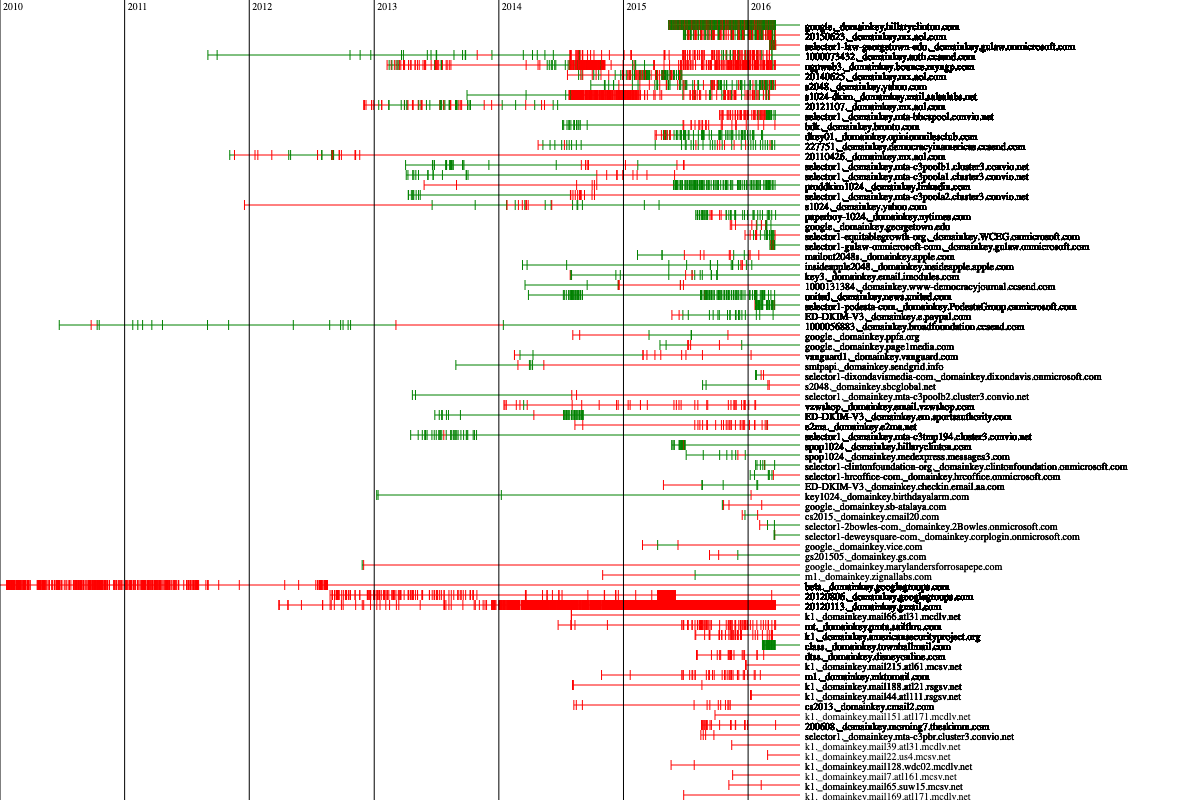 A visualization of which Clinton emails could be cryptographically verified with current values in DNS (green) versus those that cannot be verified due to missing keys (red).
A visualization of which Clinton emails could be cryptographically verified with current values in DNS (green) versus those that cannot be verified due to missing keys (red).
It turns out that there's a very interesting way to take two old signatures, and rederive an old public key! Here's concretely how:
Recall this is the format of RSA Signature and verification process, where e = 65537 usually:
RSA Signature:
Verification:
So if we have two signatures with the same modulus and exponent, but different messages, we can kind of 'write out' the modulus part as adding in a multiple of the modulus:
Signature 1:
Signature 2:
Because , we know that for some and :
And then if we subtract the message from the total mod two, we can then calculate and .
Then we take their GCD to get n: and then divide by small prime factors in case .
This is pretty big, because now any two emails from the same sender with the same public key lets us get it back! So now, during scrapes, we also cache temporarily the sender domain and selector, as well as the timestamp, and the hash of the header () and the signature () of that hash. Note that this we cannot deanonymize the user later or make fake proofs of ownership of that email, since we would have to reconstruct the preimage of the header hash to do so -- and that has as input an unknown, 256-bit body hash that we cannot guess.
Now, every time we see a new email, we check any other emails from that domain and selector just before and just after that timestamp, and if those exist then we can run the GCD method and recover the public key! In the registry, you can see this under 'reverse engineered', for instance this is how we got many old Gmail.com keys. We still need to add this feature to the Gmail upload section of the archive, but it is a high priority issue that we hope to address soon.
The Future
We still have a number of edge cases and quality-of-life improvements to make to the archive in ~27 Github Issues, that we are excited to help new contributors address.
We also want to upstream an archive check into the main DKIM verification libraries offered by various packages so that if it cannot get a matching key from DNS, it can still check against this archive and report a pass with a big warning about having to trust the archive to deliver the key correctly.
Finally, we want to give this tool to journalist tech teams -- it can be super valuable to analyze old email leaks and be able to verify their provenance; we've already seen lawyers request these old keys before.